译者按:大部分人都知道,百兆以太网只用了 RJ45 端口中的 2 对 4 根线,分别为 TX、RX 的差分信号。
本文是“攻玉计划”的一部分,翻译自 https://www.practicalnetworking.net/stand-alone/ethernet-wiring/
当我们谈到“以太网”的时候,我们可能会讨论各种概念,包括所有线缆规格(10BASE-T, 100BASE-TX, 1000BASE-T 等等)。这些协议规定了导线上的电平(即 0/1 信号)是如何传递的,也规定了如何将电平信号解析为数据帧。
本来,此文只想简单介绍一下交叉线和直通线之间的基本区别,但基于我们的 原则 ,我们觉得应该更深入一些。
首先,我们会先介绍一些术语,并消除一些歧义,然后回答一些基本的问题:我们为什么要用交叉线或者直通线?到底什么是双绞线?一个个比特位是如何在线上传播的?最后,我们会综合这些概念,并探讨一下千兆以太网的相关标准。
术语解释 即使你刚接触网络通信不久,也应该听说了很多网线相关的概念,例如“以太网”“双绞线”“RJ45”“屏蔽线”“非屏蔽线”等。
但这些概念代表了什么含义?互相之间又有什么异同?有没有什么概念被误用了?坦白而言,这些概念经常被误用,不妨看看:
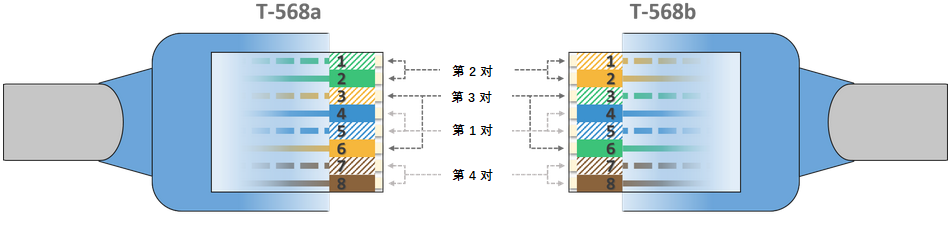
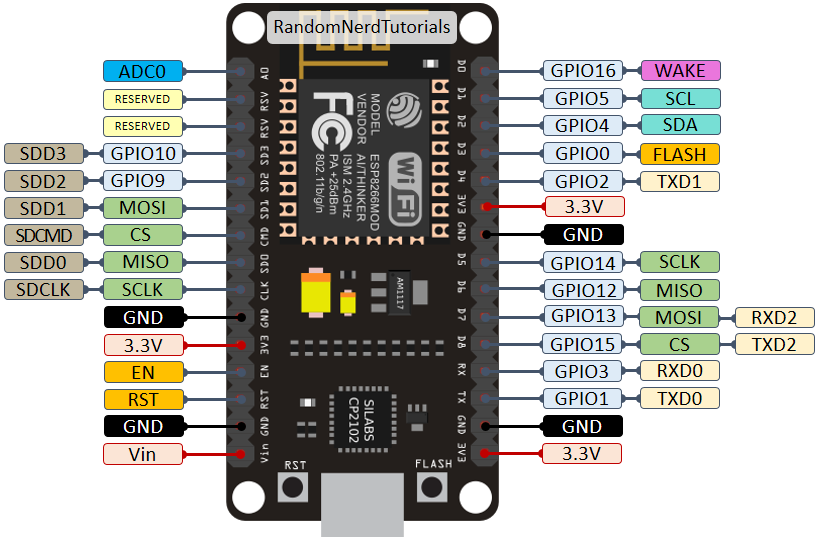
8P8C 这是网线两端接口的物理标准,表示它有 8 个卡口位(Position)和 8 个触点(Contacts)。这也定义了此塑料透明接口的外形设计和尺寸。
RJ45 标准插座接口(Registered Jack)第 45 号标准定义了线缆中导线的个数以及线序,并规定使用 8P8C 的物理接口。
特别地,RJ45 定义了两种线序标准:T568a 和 T568b:
请注意,两个标准唯一的实际区别是第 2 对线和第 3 对线的颜色不同。
很多人经常用 RJ45 来指代 8P8C 插口,但这是不对的。还有另一种叫 RJ61 的类似标准,也使用了 8P8C 的插口,但其内部的线序不一样。标准插座接口定义家族中还有很多其他 RJxx 的接口,但接线定义和物理尺寸都不一样。
双绞线 双绞线是一种组合线缆,包含了 8 根独立的导线,其中每两根作为一对,每对的两根线互相绞绕在一起。由此得到 4 对导线,每对导线作为一个数据传输通道。
导线成对出现这一概念很重要,我们在后文中会讲到,简而言之,这有助于减少电磁干扰(EMI)。
通常,双绞线有两种规格:屏蔽线 及非屏蔽线 。
注意,不管哪种规格,网线中都有 4 对导线,也就是 4 个独立的数据通道。
非屏蔽线 非屏蔽线(Unshielded Twisted Pair)(UTP)在实际工程部署中更为常见。它对外部的电磁噪声没有额外的防护,但得益于双绞线的固有特性,其数据传输也非常可靠。我们将在后文详细阐述。
非屏蔽线更便宜,物理韧性更好,也更软。这些优点使得非屏蔽线在大多数场合更受欢迎。
屏蔽线 屏蔽线(Shielded Twisted Pair)(STP)在每对双绞线、以及全部 4 对导线最外侧都包有额外的金属屏蔽壳,这有助于隔离信号传输时的电磁噪声。
但同时,如果屏蔽壳的某个地方出现了破损,或者屏蔽壳在网线两端没有都良好接地,它自身可能会成为一个天线,并且会因为空间中随处可见的无线电波(比如 Wi-Fi 信号)而给信号传输带来额外的电磁噪声。
更为甚者,屏蔽线必须与带屏蔽的 8P8C 插头一起使用,才能实现全链路端到端的屏蔽功能。
显然,屏蔽线肯定更贵,也比非屏蔽线更脆弱,因为如果屏蔽线被过度弯曲的话,其屏蔽壳很容易破损。因此,屏蔽线的使用场合比非屏蔽线少得多。
屏蔽线通常只会用在对电磁屏蔽高度敏感的场合,例如,网线紧挨着发电机或者重型机械的输电线等。
以太网 就像我们之前说的,以太网(Ethernet)是一系列标准的合集,其中之一就是不同的接线规格:10BASE-T,100BASE-TX,1000BASE-T 等等。
以太网协议也定义了每个比特(1 和 0)如何在线缆上传输,以及如何将这些比特流组合为有意义的数据帧。例如,以太网规定每帧数据的前 56 个比特必须是交替出现的 1 和 0(即“前导码”),接下来 8 个比特必须是 10101011(即帧起始标志),再接下来 48 个比特是目标 MAC 地址,然后是 48 个比特的源 MAC 地址……直到整个数据帧被全部传输完毕。
接下来,我们将讨论以太网标准中不同规格的接线规格。
BASE T* 相关术语 本节讲述的概念都与网线内部的导线如何使用相关。例如,哪些用来发送数据,哪些用来接收数据,如何发送信号,以及电压等级。
BASE T* 这一概念有三个组成部分,所以在我们讲述特定的标准之前,先来单独了解一下它们,以 100 BASE-T 为例:
100BASE-T 中的“100” 开头的数字表示网线每秒可以传输多少“兆(百万)”比特,即 Mbps。100Mbps 的网线理论上每秒可传输 100,000,000 个比特,大概每秒 12.5 兆字节(MBps),注意大写的 B 和小写的 b 分别代表字节和比特。
这一速率的网线有时被称为“快速以太网”,这是相较于 10Mbps 的“普通以太网”以及 1000Mbps 的“吉比特以太网”而言的。
100BASE-T 中的“BASE” base 这个概念是“基带”(baseband)信号的缩写,对应的概念是“宽带”(broadband)信号。这些概念刚出现的时候,其区别是:基带在介质中传输数字信号,宽带在介质中传输模拟信号。
数字信号和模拟信号的区别在于其可被解析的值个数。
模拟信号可以表示无数种不同的值,例如,我们可以用一根线上某个特定的电压值来表示一个绿色的像素点,而另一个电压值来表示红色的像素点,以此类推,这样,这根线就能传输一张图片上的每一个像素点。
数字信号可以表示有限个不同的值,通常就两个:1 和 0。如果上述的图片用一根数字信号线来传输的话,我们会传输一系列 1 和 0 的信号流。接收端可以解析这些二进制数据为一系列数字,例如基于 RGB 颜色编码 ,就能构造出每一个像素点。
也就是说,数字信号和模拟信号的主要区别就是,模拟信号线上可获得无穷多中不同的值,而数字信号线上,要么是 0,要么是 1,不可能出现第三种情况。
如此一来,数字信号传输具有更高的容错率,因为导线上的电压范围只被分为了两种情况(1 或者 0)。
译者按:原文在此处举了更多的例子来详细阐述“模拟信号”和“数字信号”的区别,但译者认为过于冗余,故略去这部分篇幅。
100BASE-T 中的“-T” “-T”表示其为双绞线(Twisted Pair)。相似的标准还有“-2”及“-5”,表示其是最大长度为 200 和 500 米的同轴电缆,以及“-SR”和“-LR”,表示其为短距离(Short Range)和长距离(Long Range)光纤。
以上解释了 BASE T* 相关术语的三个独立部分,我们现在可以探讨下快速以太网的两个重要规范(对于吉比特以太网的相关规范,我们会在后文继续探讨):
100BASE-T4 100BASE-T4 使用了网线中全部 4 对 8 根线。其中一对仅仅用于发送信号(TX),一对仅仅用于接收信号(RX)。剩下两对既可以用于 RX 也可以用于 TX,这通过网线两端设备的协商来决定具体用途。
T4 是双绞线早期的标准之一,但由于其过于复杂且必要性不强,如今已很少使用。
100BASE-TX 100BASE-TX 只使用了网线中的 2 对 4 根线,其中一对用于 TX,另一对用于 RX,剩下两根线没有使用。你完全可以做一根只有 4 根线的网线以实现 100BASE-TX 的所有功能,只要插口触点位置正确即可(位号1,2,3,6),但通常网线铺设过程中,另外 4 根线也保留了下来,用于占位,并适配未来可能的场景升级。
100BASE-TX (包括全部 8 根线)是如今最常用的快速以太网标准。但是,它通常被简写成了 100BASE-T。再强调一下,T 只表示其为双绞线,而 TX 才表示其使用了 1&2 及 3&6 两对线。
以上介绍可从实用性和技术性的角度帮读者理解相关概念。而在实际情况中,即使你不理解原理,直接使用这些产品也非常简单,就算犯一些小错误,也是允许的。
为什么使用交叉线 网上能找到很多“交叉线”及“直通线”应用场景的相关教程,但他们一般很少解释其原理。本节我们会深入探讨一下相关概念。
100BASE-TX 及 10BASE-T 标准中定义的网线,都包含 8 根导线,两两以双绞线的形式结合为 4 对。
在这四对线中,实际只用到两对:第 2、3 对。每根线都是单工的介质,也就是说,信号只能按照指定的单方向传输。
为了实现全双工通讯,某对线将始终沿某个方向传输数据,而另一对线将始终沿相反的方向传输数据。
网络接口卡(Network Interface Card)(NIC)的配置会决定哪对线用于发送数据,哪对线用于接收数据。
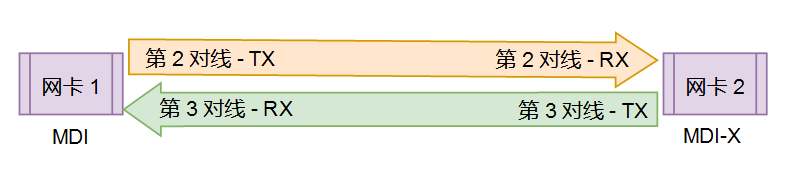
使用第 2 对线(1 号和 2 号引脚)发送数据(TX)、且使用第 3 对线(3 号和 6 号引脚)接收(RX)数据的的 NIC 被称作介质相关接口(Media Dependent Interface)(MDI),与之相反,使用第 3 对线作为 RX、第 2 对线作为 TX 的 NIC 被称为交叉模式介质相关接口(Media Dependent Interface Crossover)(MDI-X)。
电脑之间直连通讯 假设一台电脑使用 MDI 模式的 NIC ,那么它就总是用第 2 对线发送数据,用第 3 对线接收数据。但如果两台用网线连接在一起的电脑都用第 2 对线发送数据,那么就会产生冲突。与此同时,两台电脑也都无法从第 3 对线上接收到数据。
因此,网线对需要交叉一下,以便从一台电脑的第 2 对线发送的数据,会被另一台电脑的第 3 对线接收到,反之亦然。
下图是一个简单的示意(无需在意示意图中线的颜色,这只是为了区分两个不通的路径而已):
注意,两台电脑都在独立的通道上发送数据,并且依靠交叉线机制(如图所示中间的 X),两台电脑都能接收到对方发送的数据。
因此,两台电脑直连后,必须使用交叉线才能通讯 。
电脑之间通过交换机通讯 交换机使得同一网络下两台电脑的通讯变得更简单。交换机的 NIC 都采用 MDI-X 标准,也就是说,交换机总是在第 3 对线上发送数据,在第 2 对线上接收数据(与电脑的 NIC 相反)。
也就是说,交换机内部有一个交叉的机制,网线本身也就不需要交叉了:
可见,连接在交换机上的电脑可以直接使用直通线 ,让交换机处理线序交叉即可。端到端的通讯路径也是一样的:每个设备都在自己的 TX 线上发送数据,在 RX 线上接收数据。
电脑之间通过两个串联的交换机 我们刚刚讨论了,两台电脑直连,需要使用交叉线;类似的,两台交换机之间也需要交叉线:
在这种情况下,端到端的通讯路径也与上述方式无异。
路由器与集线器 那么,路由器和集线器呢?他们用了怎样的 NIC ?
实际情况是,路由器与电脑类似,使用了 MDI 标准(第 2 对线是 TX,第 3 对线是 RX),因此,你可以将上述图片中的任意电脑换成路由器,通讯路径分析也是一样的。
而集线器与交换机类似,使用 MDI-X 标准。
译者按:此处的“路由器”是狭义上仅具有“路由”功能的设备,不等于常见的家用无线路由器
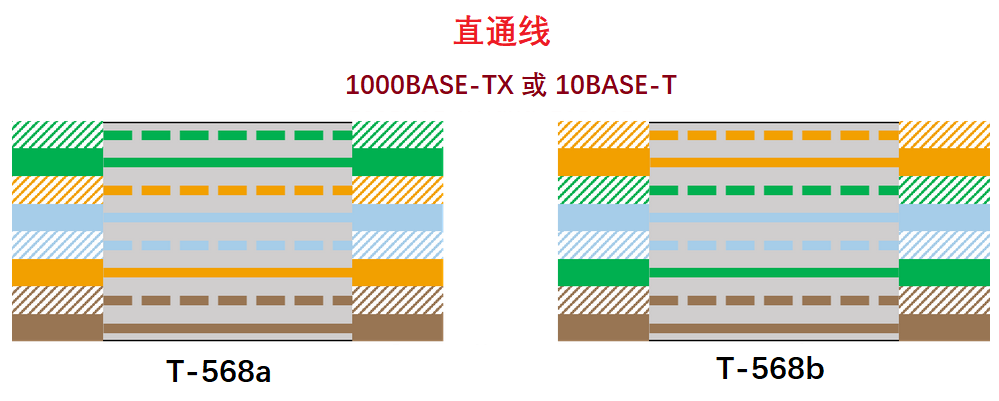
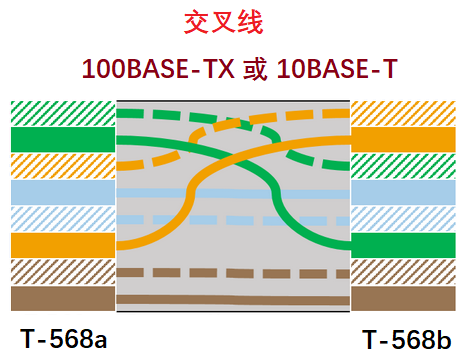
以太网线序图 前文讲到,RJ45 的导线颜色有两种标准:T568a 和 T568b。双绞线两侧所使用的标准决定了其是交叉线还是直通线。
要想做一根直通线,只要保证线两端的标准一致就行了,都是 T568a 或者都是 T568b:
要想做一根交叉线,只需其中一端为 T568a,另一端为 T568b 即可。
注意,第 1 对线和第 4 对线没有使用(蓝色对和棕色对)。理论上你的网线中可以去掉这几根线,但是去掉之后剩下的线排列起来有些困难。
另外,这两对线因为用不到,所以无需交叉。但是,吉比特以太网标准需要用到全部 8 根线,所以为了一致性,通常所有网线对都被交叉。我们会在后文讨论吉比特以太网。
最后需要注意的是,数据信号本身并不在乎导线的颜色,只要它们连在了正确的接口上就能通讯。但能用不代表就是一个好主意,颜色乱接的话,后续维护起来就是噩梦。
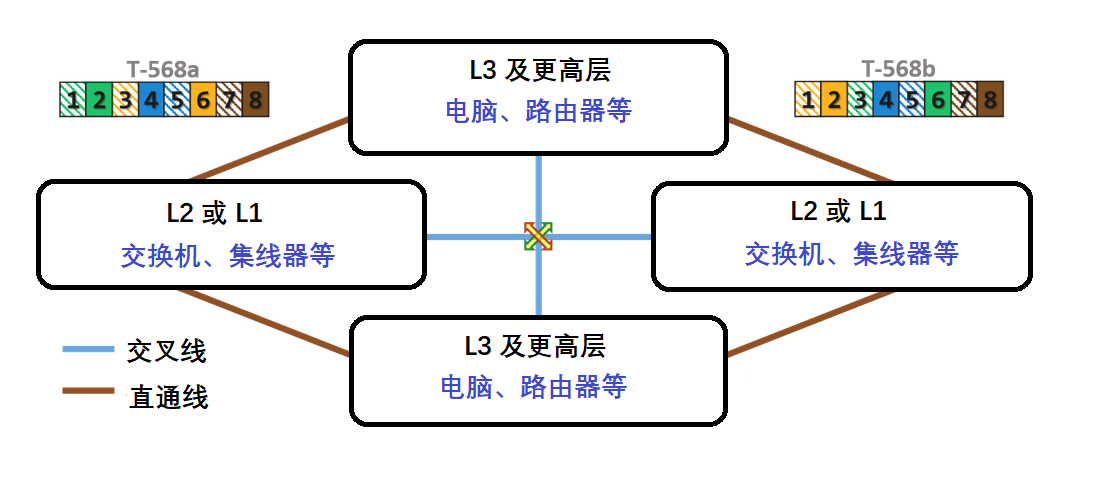
助记图 综上所述,我们可以把交叉线和直通线的用法画作一张图:
之所以这么摆放,是因为这样画起来更方便。我们把 L1、L2 层的设备画在左右两侧,L3 层设备画在上下两边,然后两两连接。关于网络协议分层请参见 OSI 模型 。
小结一下:
L1/L2 层设备互相连接,需要交叉线 ; L1/L2 层设备与 L3 层设备连接,需要直通线 ; L3 层设备互相连接,需要交叉线 。 或者更简单:
自动 MDI-X 即使知道了什么时候该用直通线,什么时候该用交叉线,对于网络工程师来说,布线也常常是个头疼的事情。
于是,出现了一个新技术,可以自动分析两台设备的接口模式,并决定是否要交叉 TX/RX。这个技术叫做“自动 MDI-X”。
使用自动 MDI-X 技术,任意两台设备之间都可以通过直通线连接,并让两端动态确定是否需要交叉 TX 和 RX。
自动 MDI-X 是 100BASE-T 实现中的一个可选功能,而在所有吉比特以太网设备中是必须的。
自动 MDI-X 的工作原理 那么,自动 MDI-X 是如何实现的?两端的设备如何确定哪对线是 TX 或 RX?如果有必要的话,哪一边的设备会交换 TX 和 RX?本节会介绍其内部工作原理。
记住,交叉线的目的是让一方的 TX 连接到另一方的 RX。也就是说,一方的 NIC 必须用 MDI 标准,另一方必须是 MDI-X 标准。自动 MDI-X 是这样实现这一功能的:
双方都先生成 1-2047 中的一个随机数,如果随机数是奇数,那么这一方会将自己的 NIC 配置为 MDI-X 模式;如果是偶数,则配置为 MDI 模式。而后双方就开始在其所选择的 TX 线上发送连接脉冲信号。
如果双方都能在自己的 RX 线上收到对方的连接脉冲,那么就代表协商完成,因为双方都能在 TX 线上发,在 RX 线上收。
如果双方都不能收到对方的连接脉冲,那么它们肯定都随机到了奇数或都随机到了偶数。因此,它们中的某一方必须将自身的 TX 和 RX 交换。
但是双方不能同时交换 TX 和 RX,因为这样一来依然是冲突的。因此,我们设计了一个系统,以随机的时间间隔切换 TX/RX 对,直到双方成功协商。
前文提到随机生成的数字(1-2047)会循环变化,以便双方能选择一个新的标准(MDI 或者 MDI-X)。但是这个数字不能每次加 1,因为这样的话,双方都会从奇数变为偶数,或者偶数变为奇数。换句话说,如果双方一开始都选择了 MDI 模式,如果同时加 1,它们都会切换为 MDI-X 模式,依然无法协商。
所以,这个随机数使用了叫“线性反馈移位寄存器”的设备以实现循环变化。
线性反馈移位寄存器(Linear-Feedback Shift Register)(LFSR)是一种算法,它会循环遍历某个范围内的所有数字,而且在每一个循环内不会重复。这些数字以一种可预测的、但随机的顺序循环出现(也就是说,它们不按照大小顺序依次出现,但出现的位置是确定的)。
举个例子,如果双方随机的初始值分别为 1000 和 2000,那么它们在 LFSR 序列中下一个数字的奇偶性是完全随机的。但如果双方随机到了同一个初始值,那么它们之后随机出来的数字依然是一样的。
这个过程会一直持续下去,直到双方成功协商。
现在问题来了,万一双方随机到了相同的数字,然后循环的时间间隔也一样呢?我们可以简单计算一下出现这种情况的几率:
双方随机到相同数字的几率是 1/2047,双方选择相同时间间隔的几率是 1/4,也就是说,双方同时切换 MDI/MDI-X 标准的几率是 1/8188。
循环每大概 62ms 运行一遍,也就是说,每秒有大概 16 个循环(每次循环开始时都会重新随机一次)。那么双方在 1 秒之内始终是相同的循环时间的几率是 1/4,294,967,296 (42 亿分之一,1/2^32)。因此,二者结合,双方在一秒内始终随机到相同的随机数、且时间间隔也一样的几率是 1/8,791,798,054,912 (8.7万亿),这种事情几乎不可能发生,就算发生了,你再等一秒就行了。
为什么使用双绞线 在网络的物理连线上使用双绞线似乎毋庸置疑。但是,为什么呢?是什么源于让双绞线在网络布线选择中处于主导地位?
有两个主要的原因,且都与电磁干扰(Electromagnetic Interference)(EMI)相关:
使用双绞线可以极大减少导线向外辐射电磁干扰; 使用双绞线可以减少外部电磁干扰对导线本身的影响。 如果网线需要长距离与其他各种线缆捆绑在一起布置(比如数据中心或者配电箱),以上两个特性都是非常重要的。
减少 EMI 向外辐射 只要导线中有电流信号,那就一定会辐射 EMI,进而影响到周围的线缆——也就是通常所说的“串扰”。EMI 辐射可以通过额外的屏蔽装置补偿掉,但是大名鼎鼎的 贝尔先生 发明了抵消电磁干扰的绝妙方法。
他的想法是使用两根导线,其中一根发送原始信号,另一根发送与原始信号完全相反的信号。如此一来,两根线会辐射恰好反向的 EMI,也就互相抵消了。
简单解释一下,如果一根线发送 +10V 的电压,并辐射了 +0.01V 的 EMI;而另一根线同时发送 -10V 的电压,并辐射了 -0.01V 的 EMI。它们的 EMI 加起来就是 0。
在电气工程中,这两根线通常被称为“差分对”,可以用 TX+ 和 TX- 来表示。
这一发明可以实现不需要大量屏蔽的布线方案,也是当前非屏蔽线得以大量使用的原因之一。
但现在我们只回答了“双绞线”中的“双”,至于为什么还要“绞”,我们继续往下看:
减少外部 EMI 的吸收 即使采用了上述的“差分线”,我们也无法避开所有外部的电磁干扰。无线网络、蓝牙、卫星通讯以及手机等都会成为空间中杂散的无线电波来源。
但幸好贝尔又出现了,并设计了一种非常简单却很有效的方案以屏蔽电磁干扰。
这一设计基于 EMI 的一个基本概念:离 EMI 辐射源越近,收到的干扰越强。如果两根线交替着靠近 EMI 辐射源,它们就能吸收同样多的辐射。如下图所示:
蓝色线的初始电压是 +50V,绿线与之相反为 -50V。EMI 辐射源为图中的红圈,一圈圈向外辐射,离中心越远的圈层干扰电压越小。如果简单将图中每根线上绘制的点受到的干扰电压相加,会发现两根线都增加了 22V 的电压。
尽管上图导线右侧的电压与左侧的不同,但是两根导线之间的电压差却总是一致的,一直都是 100V。EMI 对两根导线的影响是等同的。经过简单的计算与变换,即可根据最终的 100V 电压差得到初始信号分别为 +50V 和 -50V,如下图所示:
提醒一下,以上 EMI 干扰相关电压数值被严重夸大了。实际上,正常情况下 EMI 带来的电压扰动是微伏(µV)级别的,即 1/1000,000 V。但原理依然是一样的。
发送比特位 上文讲到,网线中的数据是以数字信号的方式发送的,也就是一串 1 和 0 的数据流。但双绞线具体是如何发送数据的呢?我们接下来会用一个简化的模型来解释一下。
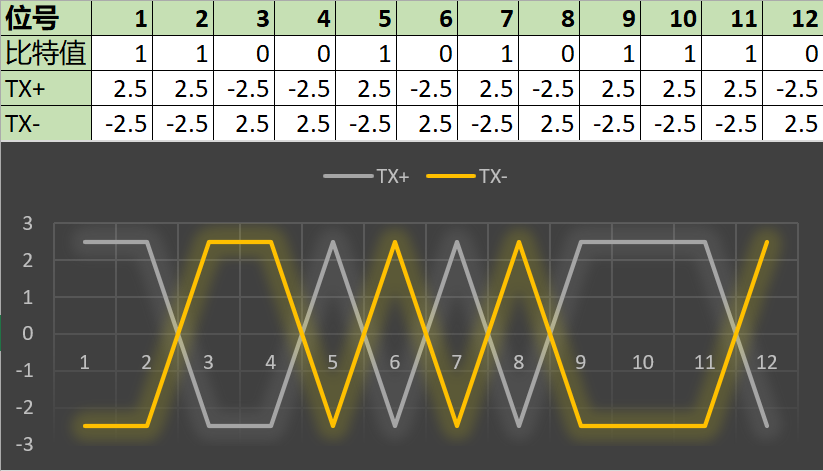
发送数据信号,本质上来说就是在某段时间内,给导线加上变化的电压。收发双方会先协商好一个时钟频率,以确定传输的每一单位的电压信号将维持多长时间。简便起见,我们称之为“位号”。在给定的时间点,每一个位号只能表示线上传输的 0 或者 1。
不同的标准会规定不同的电压等级,但由于我们简化了模型,所以不用管真正的电压是多少。但我们依然会使用 100BASE-TX 标准所规定的电压等级,即 +2.5V 和 -2.5V。
如果要在某个位号上发送比特 1,发送方会向 TX+ 线上施加 +2.5V 电压;如果要发送比特 0,就向 TX+ 线上发送 -2.5V 电压。
而 TX- 线则始终相反,比特 1 是 -2.5V,比特 0 是 +2.5V。
下表是发送 110010101110 二进制序列的相关情况:
注意上图不是网线的实体布局,只代表 TX+ 和 TX- 线上交替变化的电压信号。双绞线实际是均匀缠绕的。
就像之前讲到的,每对中的两根线上的电压总是互为相反量,一切都很整齐,且在水平方向上是对称的。
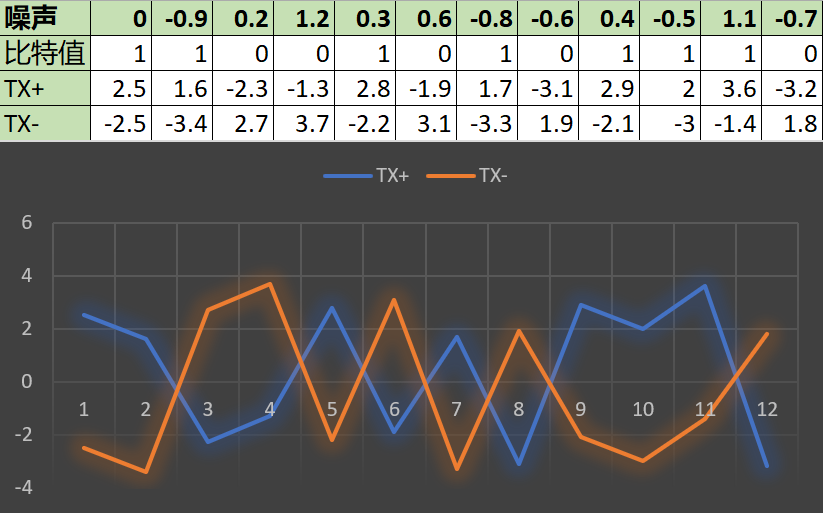
现在假设网线附近有 EMI 辐射源,我们在上表中添加一行噪声数据,然后看看最终会变成什么样:
注意到,现在这幅图已经不再对称了。两根线仍然发送相反的电压,但加了一个偏置量。
但是,接收端并不一定要完美的 +2.5V 和 -2.5V,它只需确定哪根线发送更高的电平。如果 TX+ 发送的是高电平,那么这个位号就表示 1,如果 TX- 是更高的电平,那么这个位号就表示 0。
或者更简单,如果上图中蓝线在上面,就代表 1,黄线在上面,就代表 0。
通过这种方式,接收端能一位一位地拼凑好整个数据,不管 EMI 对原始电平有怎样的干扰。可见,非屏蔽线不能消除电磁干扰,但能消除电磁干扰的影响。
吉比特以太网 我们已经详细介绍了快速以太网(100Mbps),现在我们继续讨论一下吉比特以太网(千兆以太网,1000Mbps 或者 1Gbps)。
首要的区别就是,吉比特以太网标准需要用到全部 4 对 8 根线,不像百兆网只用到 2 对。因此,在制造吉比特以太网网线时,全部 4 对线都需要交叉。
前文讲到,RJ45 有两种不同的标准:T-568a 和 T-568b。下图描绘了 4 对线都交叉它们各自的样子:
也就是说,吉比特以太网需要自动 MDI-X。所以,你可以直接在千兆网络中使用直通线,然后让网卡自动选择是否需要交叉。
吉比特以太网有两种布线标准:
1000BASE-TX 此标准使用了全部 4 对线,但规定了其中两对线为 TX,另外两对线为 RX。
理论上讲,这比 1000BASE-T 更简单,但是这需要更昂贵的 Cat6 网线,而不是常见的 Cat5 或 Cat5e 网线。因此,1000BASE-TX 在实际部署中并不常见。
1000BASE-T 这是当前应用最广泛的吉比特以太网标准。它以全双工模式同时使用了全部 4 对线,也就是说每对线都可以同时 用作 RX 和 TX。这是通过“回声消除”技术实现的,我们会在下一节详细阐述。
使用这种线序标准的最大优势是,你可以在现有的 Cat5e 网线上跑到千兆,而无需升级到更贵的 Cat6 网线。
1000BASE-T 经常被错误地指代 1000BASE-TX。这可能是因为在快速以太网协议中,占主导地位的标准是 100BASE-TX。另外很多时候,线缆标准也经常合起来称作 10/100/1000 BASE-TX。实际上,各个不同速率下,占主导的以太网协议分别是 10BASE-T、100BASE-TX 以及 1000BASE-T。
在同一对线上实现全双工 上节说到,1000BASE-T 标准可以在同一对线上同时发送和接收数据。在本节我们将解释这是如何实现的。首先,我们来做一个简单的类比。
你应该有过这样的经历:在跟别人通电话时,如果对方开了免提,你就能在听筒中听到自己的声音。这是因为你的声音从对方的扬声器中发出,在空间中遇到障碍物反射,又被对方的麦克风接收。这就叫做回声。
高端的电话可以从麦克风收到的声波中剔除扬声器发出的声波——这个技术就叫做回声消除。
回声消除也是吉比特以太网能够在同一对线上同时发送和接收数据的基础。基本原理就是,如果你知道你发送了什么信号,那么你就能从你收到的信号中将其剔除。
前文讲到,发送信号本质上是往导线上施加电压。反之,接收信号就是读取导线上的电压值。
如果发送方往某根导线上施加了以下电压:
同时,也是发送方,它在同一个导线上读取到了以下电压值:
那么,发送方可做一个减法,用读取值减去其发送的值,这样就能得到对方往这根线上加了多高的电压:
如此一来,同一根线就能在同一时间,同时发送和接收数据了。
再次强调,上述电压值仅仅为了解释原理,实际情况下,电压值可能完全不同,还会包含 EMI 等。同时,我们刚刚只讨论了双绞线中的一根线,另一根线仍然会承载反向的电压。
使用这种技术,全部 4 对线都可被同时用作 TX 和 RX。另外与前面几节的讨论相同,由于采用了双绞线,它们都还会消除入方向和出方向的 EMI。
总结 读到这里,你应该对以太网和双绞线的知识点有一个宏观的理解了。这些年我们学习并整理出了这篇文章,原来看似简单的网线居然囊括了这么多技术点,现在感觉很对不起那些被我随便就扔掉的网线了。
以太网线充满了许多我们本以为理所当然的技术,但实际却很复杂。本文为了便于理解,也省略了很多细节,如果读者有兴趣可以继续研究。
]]>